
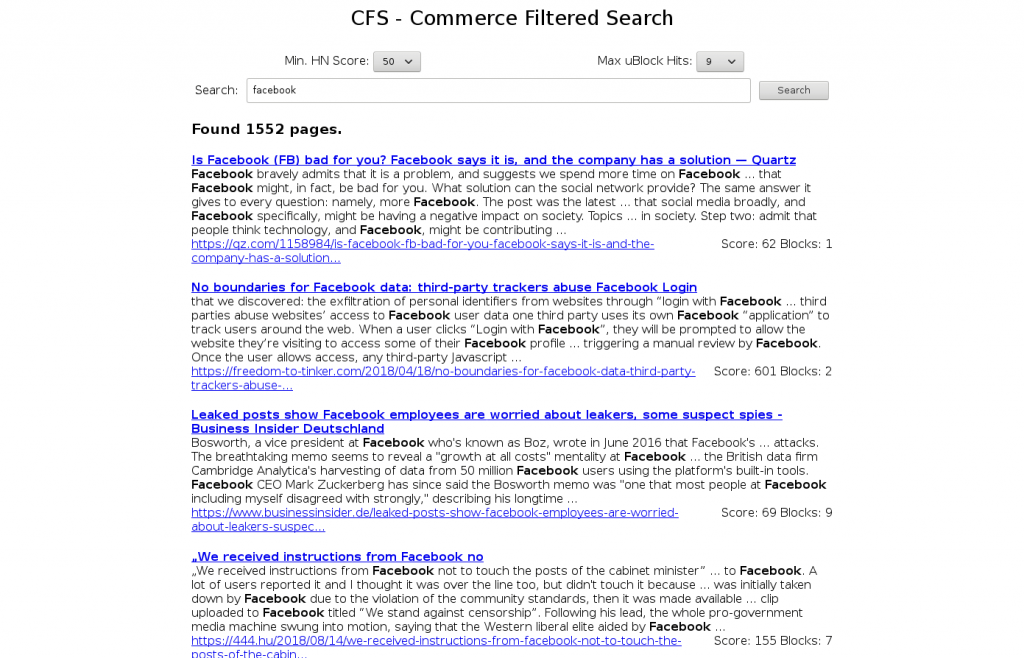
CFS is a proof-of-concept search engine that is seeded only with links from ‘high quality’ sources. Each page indexed passes through uBlock Origin, and the hits that this generates are recorded in the index. You can filter results on how ‘ad-driven’ the pages are, so I have called this Commerce Filtered Search.
For now, the only source of links has been Hacker News, there are maybe 5 million pages from that source alone. The next source to bring on board will likely be the heavily moderated subreddits.
To be clear, this isn’t searching Hacker News (or Reddit), but rather the pages that people link to when posting to these sites. That’s phase-1.
Phase-2 will take the links from the pages in the index, and index them too; the second level index. There may be a phase-3.
Since we record uBO hits for every page in the index, search results can be filtered by how invasive the hosting site is – you choose the maximum number of uBlock Origin hits allowed in the pages returned in your search results.
Let me set expectations
The index is currently small, less than 1 million pages.
The interface is rudimentary, but you can already use “phrase searching” +mustHave -mustNotHave queries as per Lucene’s classic query parser.
The server and index are being developed and might break or temporarily disappear once in a while.
I think it gives interesting search results, which is why I’m opening it up at this stage. Feedback is welcome (email kevin at susa dot net or use the comments).
This is alpha software. Please don’t try to break it, but do feel free to stretch it.
The URL of the server will probably change, but this page you are reading here will remain. If you want to bookmark anything related to CFS, then make it this page.
It turns out the commerce-filtering aspect is, thanks to the high quality of HN contributions, currently about 85% moot – there’s not a lot of click-bait on HN! I expect the uBlock scores will be more important as the index fans out to secondary links.